Foundation VAE for CT Reconstruction, Augmentation, and Generation
* Equal contribution
Abstract
We show that a single Foundation VAE, pretrained on natural images and videos, can serve as a unified training-free interface for CT reconstruction, augmentation, and generation. With frozen encoder and decoder, reconstructions preserve anatomy while suppressing acquisition noise, and training segmentation models on reconstructed CT improves boundary quality. In the same latent space, a conditional latent diffusion model generates anatomically consistent healthy and abnormal CT with explicit anatomy and report conditioning.
- +3.9% average NSD improvement for pancreatic tumor and lung tumor segmentation.
- 3.9% lower average FVD and 36.2% higher CT-CLIP score for CT generation.
- +2.76% AUC gain on 18-type downstream multi-label disease classification.
Method Overview
The framework has three connected parts: (1) CT reconstruction using frozen Foundation VAE, x~ = D(E(x)); (2) CT augmentation by using reconstructed volumes as a boundary-stable training view; (3) CT generation by conditional latent diffusion in the same fixed latent space with organ masks, disease masks, and radiology reports.
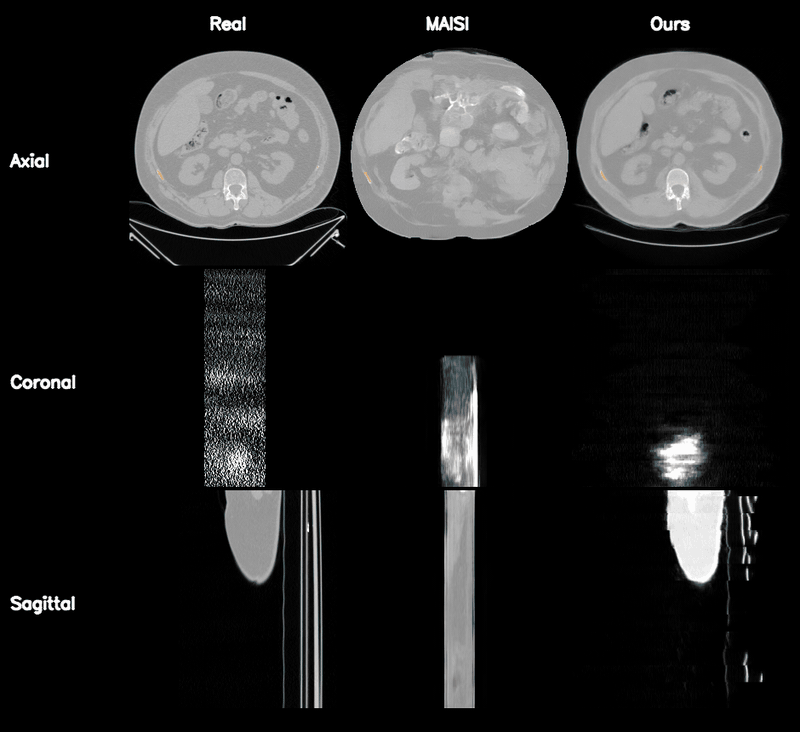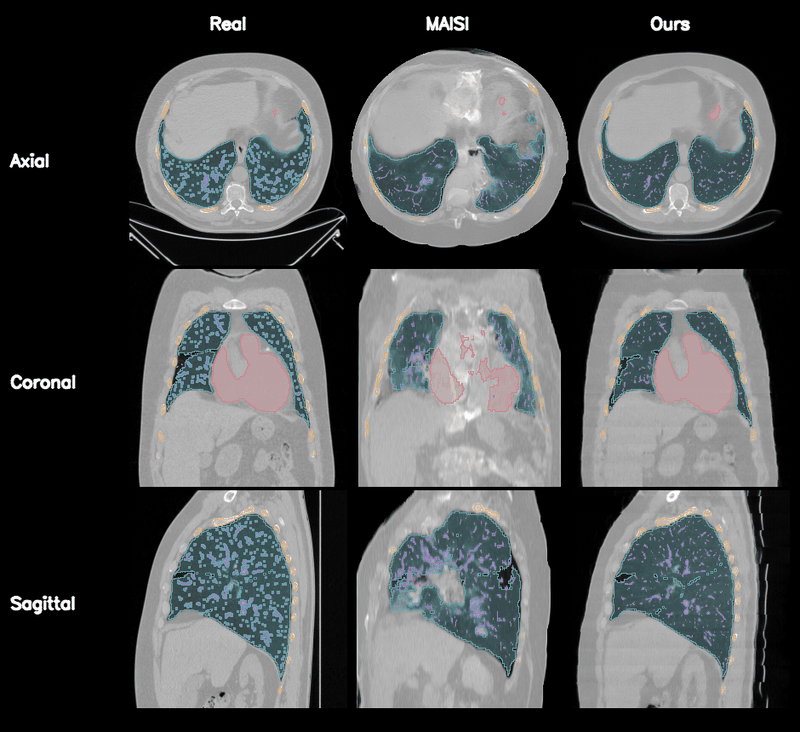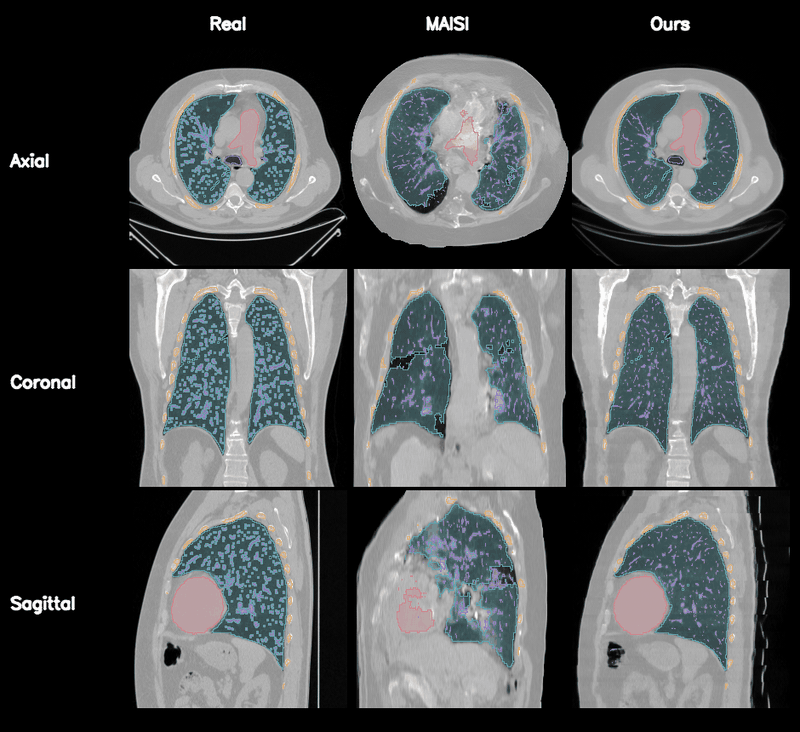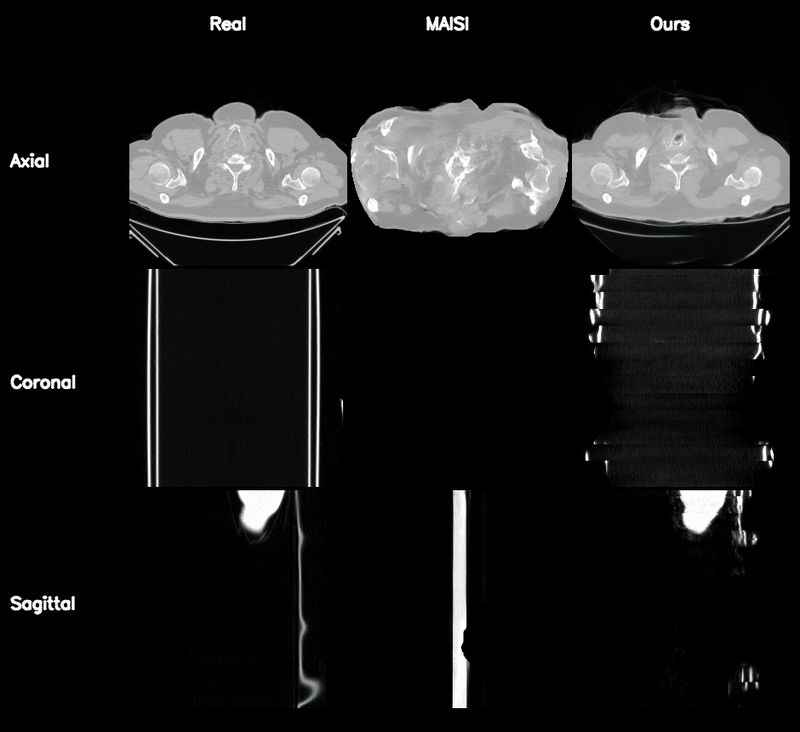
Qualitative Results
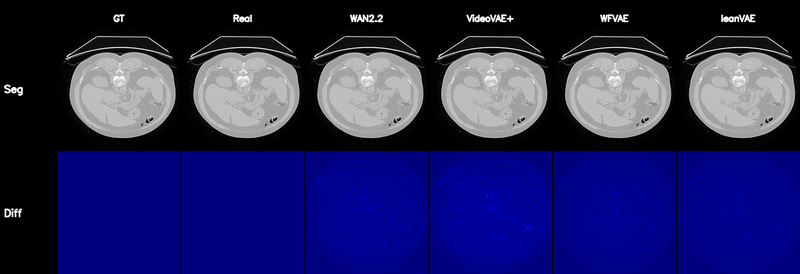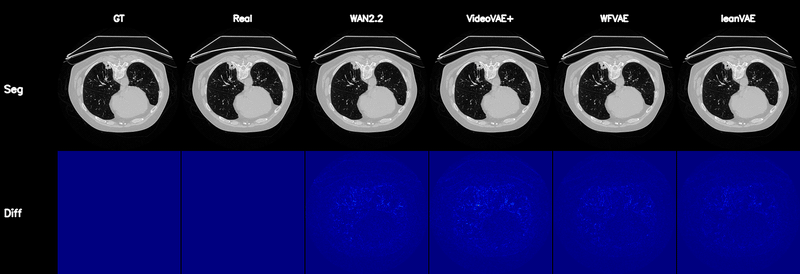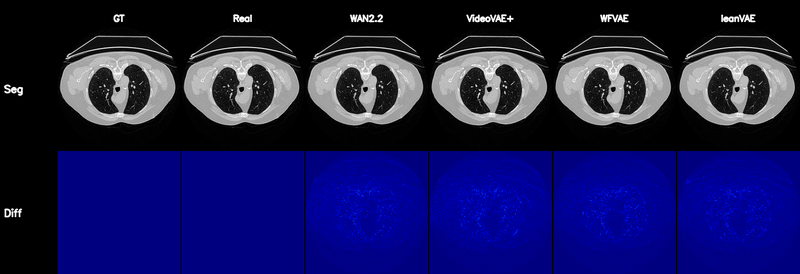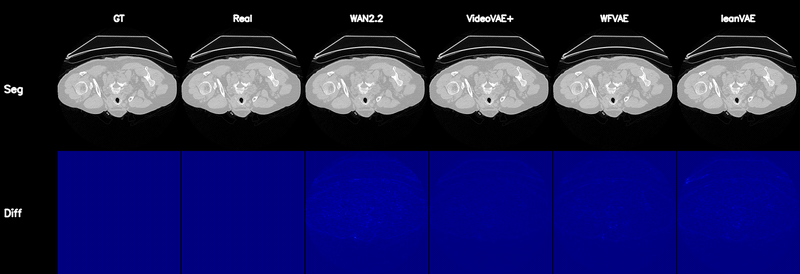
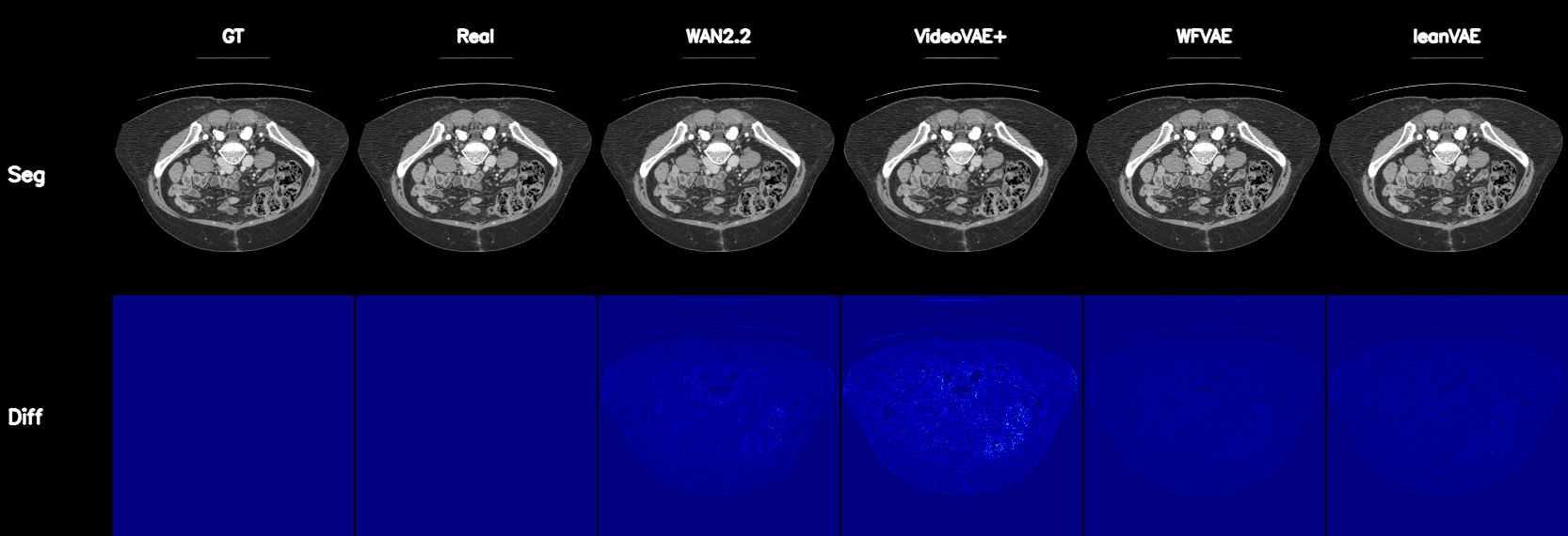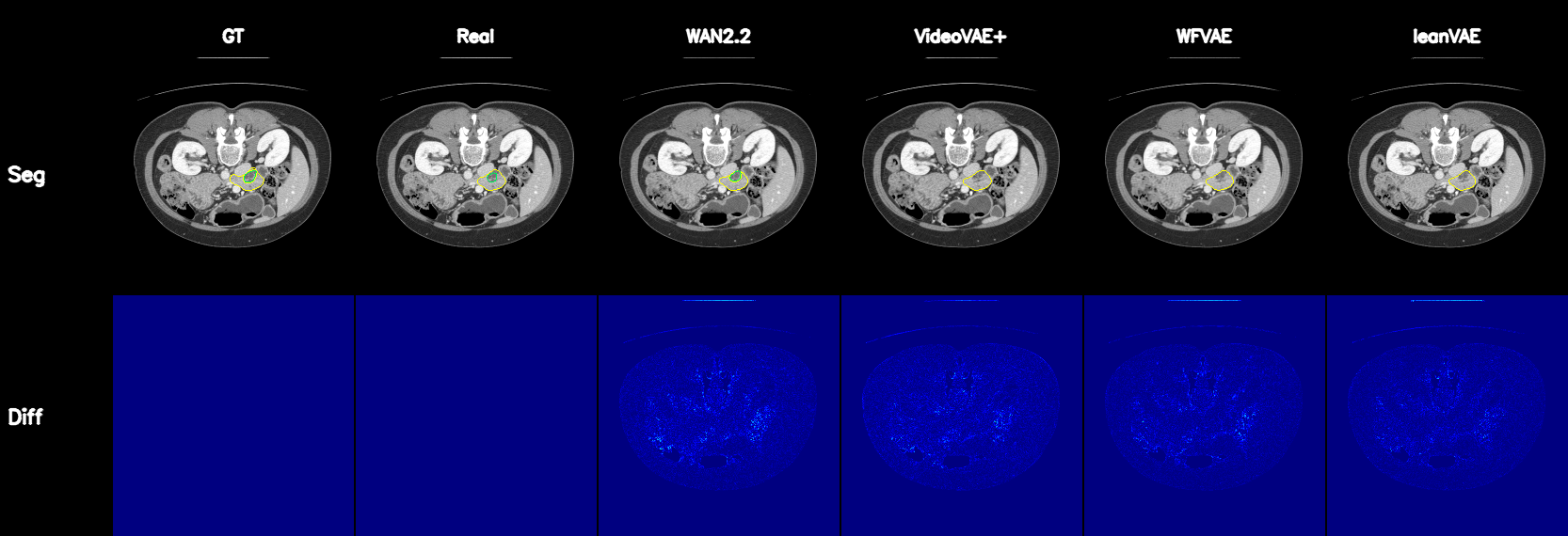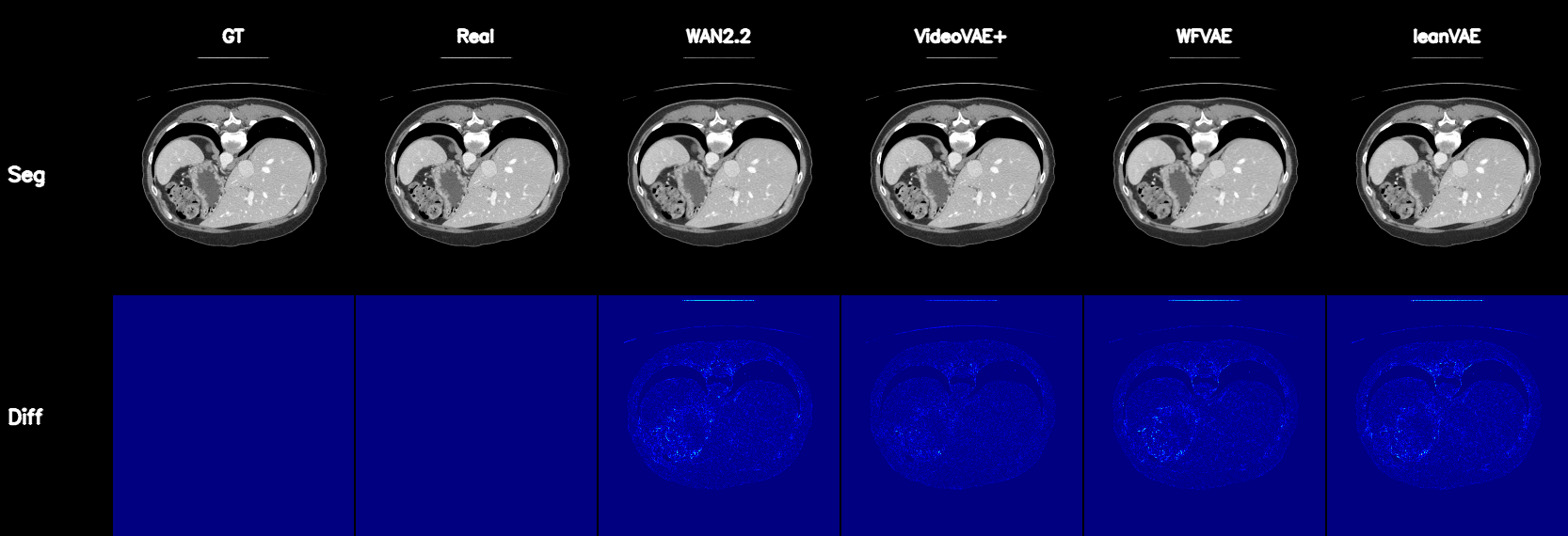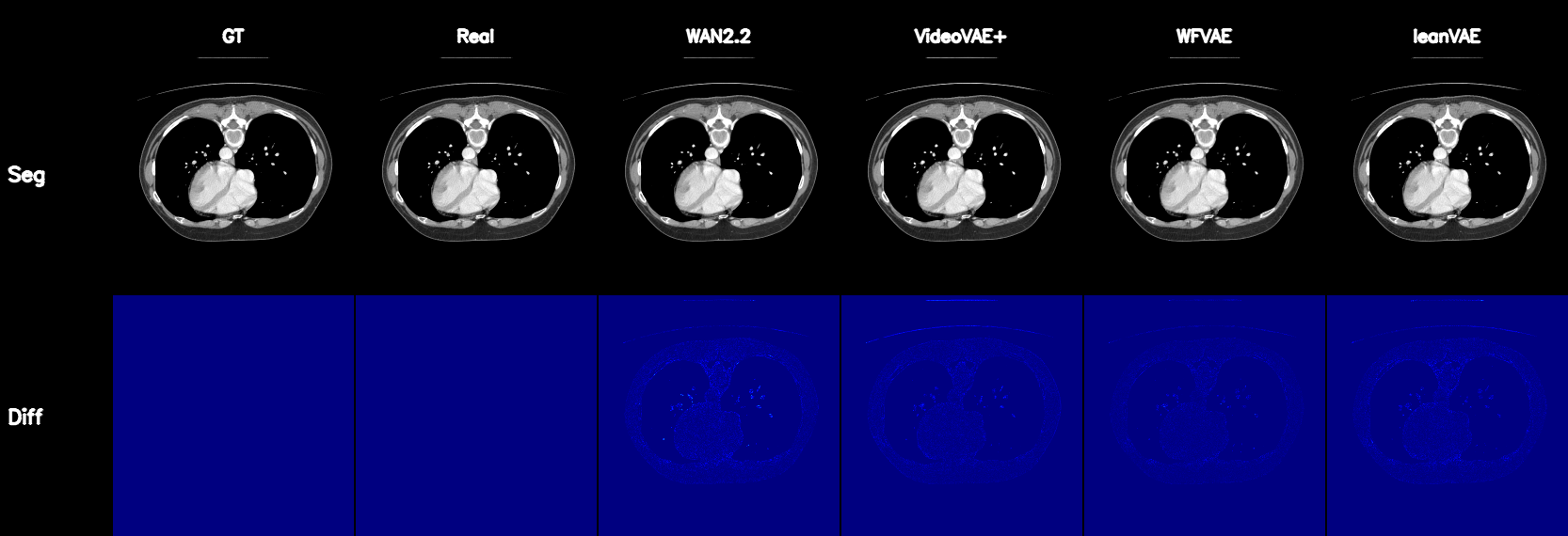
Controllable CT Generation
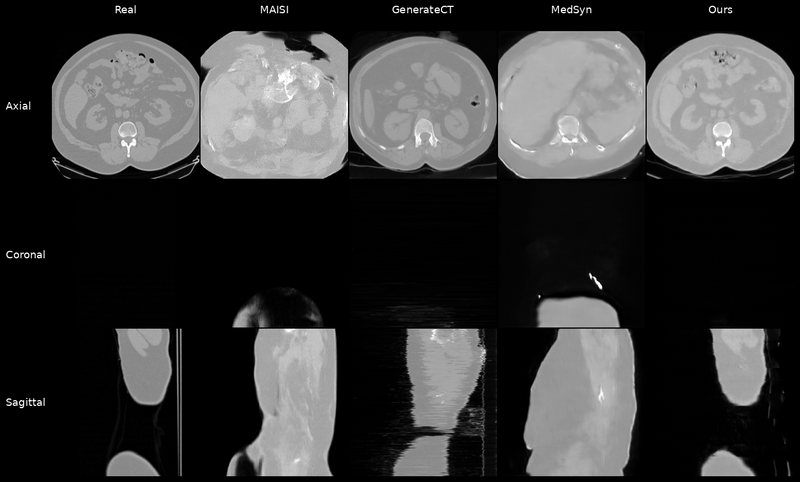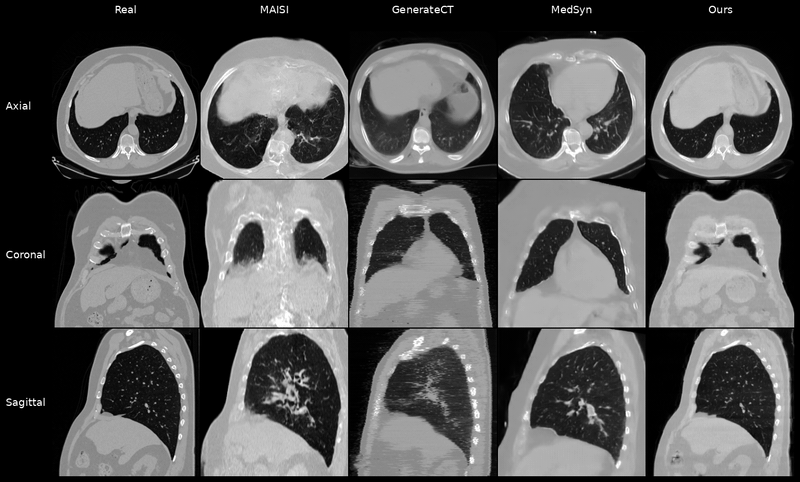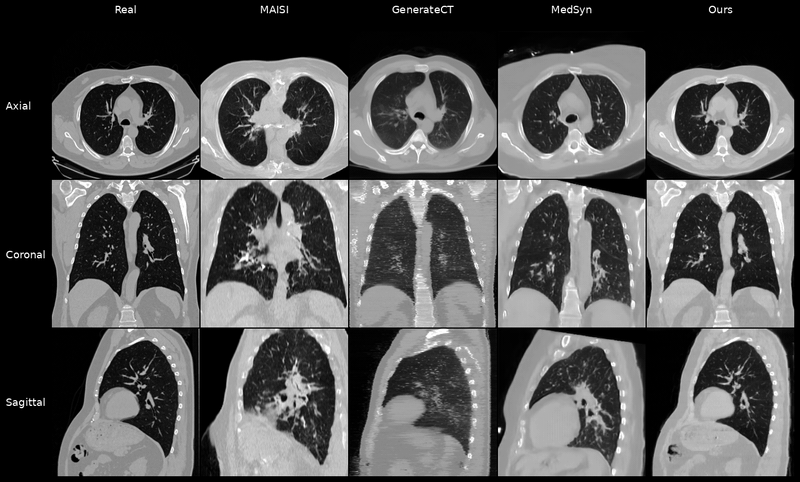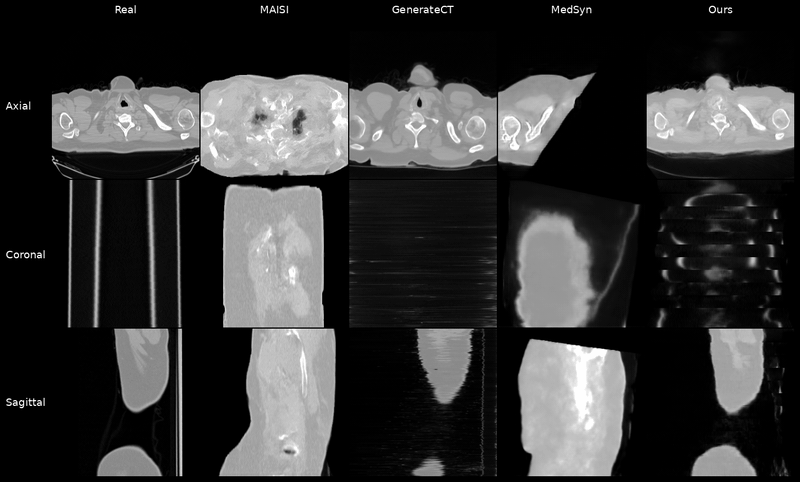
Anatomical and Pathological Grounding
BibTeX
@article{chen2026foundationvae,
title = {Foundation VAE for CT Reconstruction, Augmentation, and Generation},
author = {Chen, Qi and Ding, Shuhan and Gu, Yu and Liu, Nan and Bian, Jiang and Yuille, Alan and Zhou, Zongwei and Fu, Jingjing},
journal = {ICML 2026 (Preprint)},
year = {2026}
}